Big Data e Big Problem¶
Normalmente si può trovare come definizione di big data la seguente:
I dati sono troppo grandi per entrare in memoria/disco rigido
Esiste però un altro problema Big:
anche su dati piccoli, il mio modello potrebbe richiedere più
risorse di quelle a mia disposizioneNei big data dobbiamo fare delle scelte¶
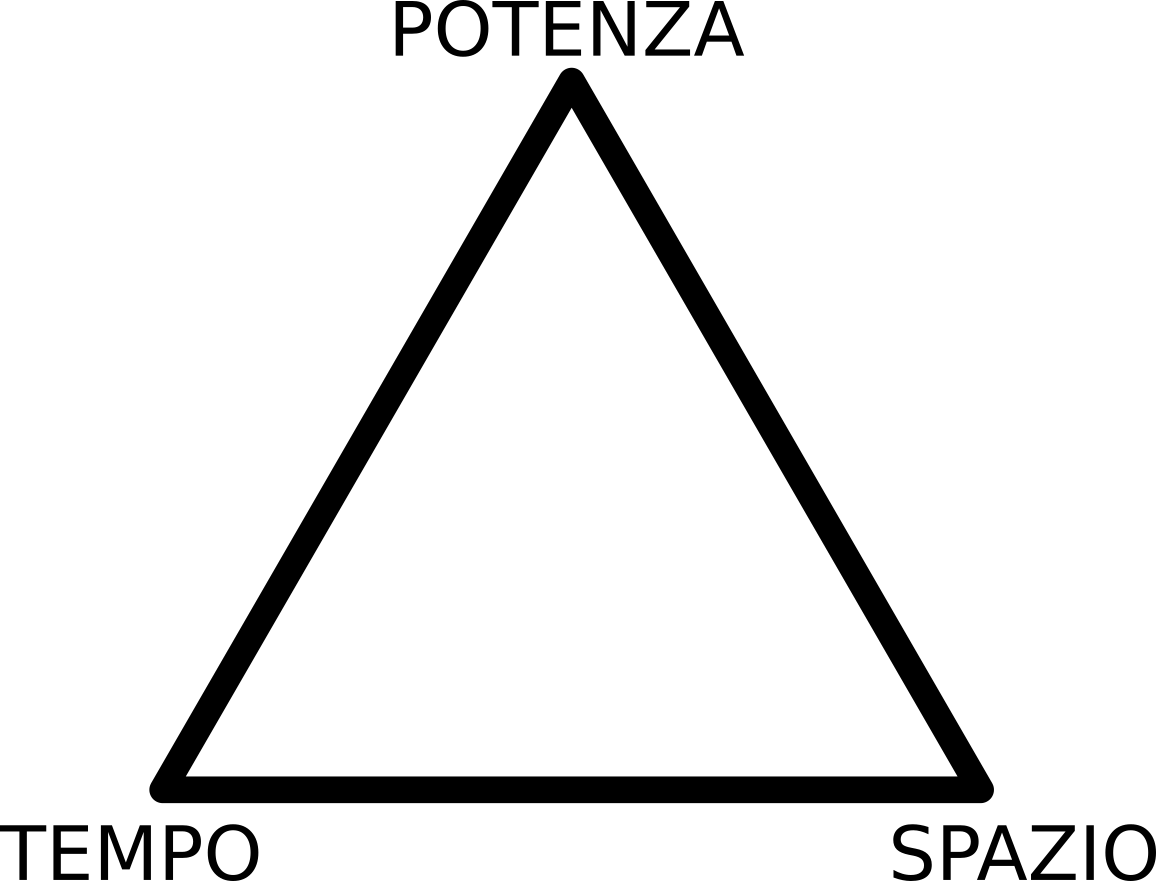
Semplificando, ci sono 3 variabili nel nostro sistema:
- il tempo che siamo disponibili ad aspettare
- lo spazio su RAM che siamo disponibili ad allocare
- l'ammontare di informazioni che vogliamo ottenere (statistical power)
Tanto più ottimizziamo uno di questi parametri, tanto più ci rimettiamo negli altri due.

Inoltre, vedremo poi, che tanto più ottimizzeremo il nostro codice, tanto più difficile sarà mantenerlo nel tempo. La comprensibilità del nostro codice ha un costo quantificabile!
Questo schema non tiene conto anche di altri fattori:
- il tradoff fra memoria su disco e su RAM
- il tempo che serve all'analista per produrre il codice
un problema di esempio - rinominare i file di una collezione audio¶
Ovviamente si tratta di un problema giocattolo.
Cosa succederebbe se i file non sono qualche centinaio, ma qualche milione?
E se per ciascun file non dovessi solo rinominare, ma fare analisi complicate?
I principi rimangono gli stessi, soltanto più estremi.
!rm -fR notebookfiles/fakeaudio
!mkdir -p notebookfiles/fakeaudio
!mkdir -p notebookfiles/fakeaudio/Albums/PinkFloyd/TheWall
!touch notebookfiles/fakeaudio/Albums/PinkFloyd/TheWall/The\ Thin\ Ice.MP3
!touch notebookfiles/fakeaudio/Albums/PinkFloyd/TheWall/Another\ Brick\ In\ The\ Wall\ -\ Part\ 1.MP3
!mkdir -p notebookfiles/fakeaudio/OST/TheBindingOfIsaac/Rebirth/
!touch notebookfiles/fakeaudio/OST/TheBindingOfIsaac/Rebirth/My\ Innermost\ Apocalypse.MP3
!touch notebookfiles/fakeaudio/OST/TheBindingOfIsaac/Rebirth/NONTOCCARE.TXT
!echo "un testo inutile" > notebookfiles/fakeaudio/OST/TheBindingOfIsaac/Rebirth/NONTOCCARE.TXT
!ls -lR notebookfiles/fakeaudio/
import os
directory = "./notebookfiles/fakeaudio/"
for basepath, listdir, listfiles in os.walk(directory):
print()
print(basepath)
print(listdir)
print(listfiles)
directory = "./notebookfiles/fakeaudio/"
for basepath, listdir, listfiles in os.walk(directory):
for filename in listfiles:
new_filename = filename.lower()
os.rename(os.path.join(basepath, filename),
os.path.join(basepath, new_filename))
!ls -lR notebookfiles/fakeaudio/
qui però sto anche cambiando il nome a tutti i file che sono presenti nelle directory, anche se non sono dei file audio!
!rm -fR notebookfiles/fakeaudio
!mkdir -p notebookfiles/fakeaudio
!mkdir -p notebookfiles/fakeaudio/Albums/PinkFloyd/TheWall
!touch notebookfiles/fakeaudio/Albums/PinkFloyd/TheWall/The\ Thin\ Ice.MP3
!touch notebookfiles/fakeaudio/Albums/PinkFloyd/TheWall/Another\ Brick\ In\ The\ Wall\ -\ Part\ 1.MP3
!mkdir -p notebookfiles/fakeaudio/OST/TheBindingOfIsaac/Rebirth/
!touch notebookfiles/fakeaudio/OST/TheBindingOfIsaac/Rebirth/My\ Innermost\ Apocalypse.MP3
!touch notebookfiles/fakeaudio/OST/TheBindingOfIsaac/Rebirth/NONTOCCARE.TXT
!echo "un testo inutile" > notebookfiles/fakeaudio/OST/TheBindingOfIsaac/Rebirth/NONTOCCARE.TXT
directory = "./notebookfiles/fakeaudio/"
for basepath, listdir, listfiles in os.walk(directory):
for filename in listfiles:
if filename.lower().endswith('mp3'):
new_filename = filename.lower()
os.rename(os.path.join(basepath, filename),
os.path.join(basepath, new_filename))
!ls -lR notebookfiles/fakeaudio/
Queste sono tre operazioni fondalmentali per l'analisi dati:
- iterazione lazy
- map (ripeti un'operazione su tutti gli elementi)
- filter (seleziona solo una parte degli elementi)
altri tipi di operazioni che discuteremo saranno:
- reduce (comporre insieme gli elementi)
- functional programming
Iterazione Lazy¶
che cosa intendiamo con iterazione lazy?
le operazioni non vengono compiute finchè il risultato non è richiesto!!
In Python questa cosa è gestita da degli oggetti chiamati iteratori.
Sono gli oggetti su cui faccio i cicli for.
Un iteratore può essere percorso una volta sola!
Questo è controintuitivo: se provo a fare un ciclo for su di una lista, lo posso fare quante volte voglio
lista = [1, 2, 3]
print("--- prima iterazione ---")
for elemento in lista:
print(elemento)
print("--- seconda iterazione ---")
for elemento in lista:
print(elemento)
ma se provo a farlo su di un file, lo posso leggere una volta sola!
Se volessi rileggerlo, dovrei aprirlo di nuovo!
directory = "./notebookfiles/fakeaudio/OST/TheBindingOfIsaac/Rebirth/"
filename = "NONTOCCARE.TXT"
position= os.path.join(directory, filename)
with open(position) as file:
print("--- prima iterazione ---")
for line in file:
print(repr(line))
print("--- seconda iterazione ---")
for line in file:
print(repr(line))
Python ce lo nasconde, ma in realtà ogni volta che iteriamo sulla lista lui crea un nuovo iteratore che scorre la lista e poi scompare.
Possiamo farlo esplicitamente con il comando iter
lista = [1, 2, 3]
iteratore_lista = iter(lista)
print("prima iterazione")
for elemento in iteratore_lista:
print(elemento)
print("seconda iterazione")
for elemento in iteratore_lista:
print(elemento)
Sottolineare quando le iterazioni non necessitano di caricare l'intero dataset è importante perchè non è sempre vero.
Supponiamo di voler calcolare tutte le combinazioni di elementi di una sequenza: non possiamo risolvere questo problema senza tenere in memoria l'intera sequenza!
Map¶
Un tipo di operazione molto frequente sulle sequenze è il cosiddetto mapping, ovvero applicare una funzione a tutti gli elementi di una lista, uno alla volta ed indipendentemente dagli altri.
Ad esempio, avendo una serie di numeri, potrei voler prendere il quadrato di ciascuno.
numeri = [0, 1, 2, 3, 4, 5, 6]
quadrati = []
for numero in numeri:
quadrato = numero **2
quadrati.append(quadrato)
print(quadrati)
Questo può essere espresso in modo pi conciso con una comprehension, che è funzionalmente identica al ciclo visto prima, ma più sintetica
numeri = [0, 1, 2, 3, 4, 5, 6]
quadrati = [x**2 for x in numeri]
print(quadrati)
il concetto di map è un'astrazione di questo procedimento.
Python fornisce una funzione, chiamata appunto map, che prende una funzione ed un iteratore e ritorna un iteratore i cui elementi sono il risultato dell'operazione
def quadrato(n):
return n**2
numeri = [0, 1, 2, 3, 4, 5, 6]
quadrati = map(quadrato, numeri)
print(quadrati)
ricordiamoci che il risultato delle operazioni sugli iteratori, quando possibile, è a sua volta un iteratore!
siamo noi che dobbiamo esplicitamente concretizzare l'iterazione
list(quadrati)
ricordiamoci che l'iterazione è compiuta una volta sola, quindi se vogliamo il risultato dobbiamo salvarcelo alla prima concretizzazione!
list(quadrati)
Filter¶
in modo simile il concetto di filter è piuttosto semplice: seleziono un sottoinsieme dei miei dati, generando un secondo iteratore.
numeri = [-2, -1, 0, 1, 2]
positivi = []
for numero in numeri:
if numero>0:
positivi.append(numero)
print(positivi)
in modo simile all'operazione di map, anche l'operazione di filter ha un costrutto nel linguaggio tramite le comprehension
numeri = [-2, -1, 0, 1, 2]
positivi = [x for x in numeri if x>0]
print(positivi)
ed esattamente come prima, abbiamo una funzione che prende una funzione di filtro (che ci dice se l'elemento è accettabile o no) e la applica ad un operatore
def is_positive(n):
return n>0
positivi = filter(is_positive, numeri)
print(list(positivi))
Reduce¶
questa operazione combina gli elementi di un iteratore in un elemento unico
numeri = [1, 2, 3, 4]
totale = 0
for numero in numeri:
totale += numero
print(totale)
come per casi precedenti, esiste una funzione preesistente per effettuare le operazioni di riduzione
from functools import reduce
def somma(a, b):
return a+b
numeri = [1, 2, 3, 4]
totale = reduce(somma, numeri, 0)
print(totale)
Questo tipo di operazioni è così comune che ci sono una serie di operazioni predefinite:
- sum per la somma
- min e max per il minimo e massimo
e così via
una tipica riduzione, che useremo molto, è la stima delle frequenze.
from collections import Counter
numeri = [1, 1, 1, 2, 2, 3, 3, 4, 4, 4, 4, 4]
Counter(numeri)
Una proprietà importante delle riduzioni è che i risultati si possono combinare: dati i conteggi su due serie, posso sommare insieme i due conteggi ed ottenere i conteggi totali fra le due serie
Map Reduce¶
il famoso metodo MAP-REDUCE è una combinazione di queste idee:
- prendo una sequenza, la divido in sottosequenze
- invio le sequenze a diversi computer
- compio una riduzione su ciascuna sottosequenza
- raccolgo le sottosequenze e le combino insieme
- tutto questo fatto in modo ricorsivo